http://www.sitepoint.com/article/hierarchical-data-database/2/
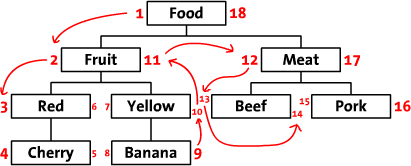
ツリーデータを2次元の表で表現する方法はそれなりにあるが、親や子の繋がりを1クエリで取得できるという意味で、上記の「Modified Preorder Tree Traversal」は特に優れている。データを更新する際にはクエリの数が増えるものの、親子関係の取得の際には、それを補って余りある利点がある。
具体的な紹介は、3年前のふじもとさんのエントリに譲る。ここでは、その内容に補足する形で、1点だけメモを記しておく。
----
このアルゴリズムは、親子関係を一気に取得する縦の演算には非常に強力だが、同じ階層にあるノードを一気に取得しようと思うと弱い。つまり、横の演算をしようと思うと、親の数が等しいものをいちいち全ノードについて計算しなければならなくなる。
よって、別に親の数を格納したカラムを持つのが一番良いのだろうと思う。親の数は以下のクエリで全く問題なく計算できるので、それをUPDATE時またはINSERT時に格納してしまえばいい。
SELECT COUNT(*) FROM tree_table WHERE lid < xx AND rid > xx;
0 件のコメント:
コメントを投稿